
 GPT-4 是 OpenAI 开发的最先进的生成式 AI。它正在改变我们的工作方式。但是,GPT-4 不是开源的,这意味着我们无法访问代码、模型架构、数据或模型权重来重现结果。我们不能像聊天机器人一样创建自己的 GPT-4。
GPT-4 是 OpenAI 开发的最先进的生成式 AI。它正在改变我们的工作方式。但是,GPT-4 不是开源的,这意味着我们无法访问代码、模型架构、数据或模型权重来重现结果。我们不能像聊天机器人一样创建自己的 GPT-4。
为了平衡规模,开源社区已经开始研究 GPT-4 替代方案,这些替代方案提供几乎相似的性能和功能,并且需要更少的计算资源。
您可以通过查看以下内容了解 GPT-1、GPT-2、GPT-3 和 GPT-4:什么是 GPT-4 以及为什么重要?,或者您可以学习使用 ChatGPT 用于数据科学项目并掌握提示工程,以更好地构建端到端数据科学项目。
在本文中,我们将介绍 12 种 GPT-4 替代品,并简要说明相关研究论文、博客文章、聊天机器人演示、代码源和模型卡的链接。
注意:提到的一些模型具有非商业许可证,这仅限于研究和学术目的。在使用它们之前,您需要了解这些限制。
1. 巨聊
ColossalChat是一个开源项目,允许您使用完整的RLHF(来自人类反馈的强化学习)管道克隆AI模型。
它是一个完全开源的项目,包括双语数据集、训练代码、演示和 4 位量化推理。所有组件都将帮助您更便宜、更快地创建自定义聊天机器人。
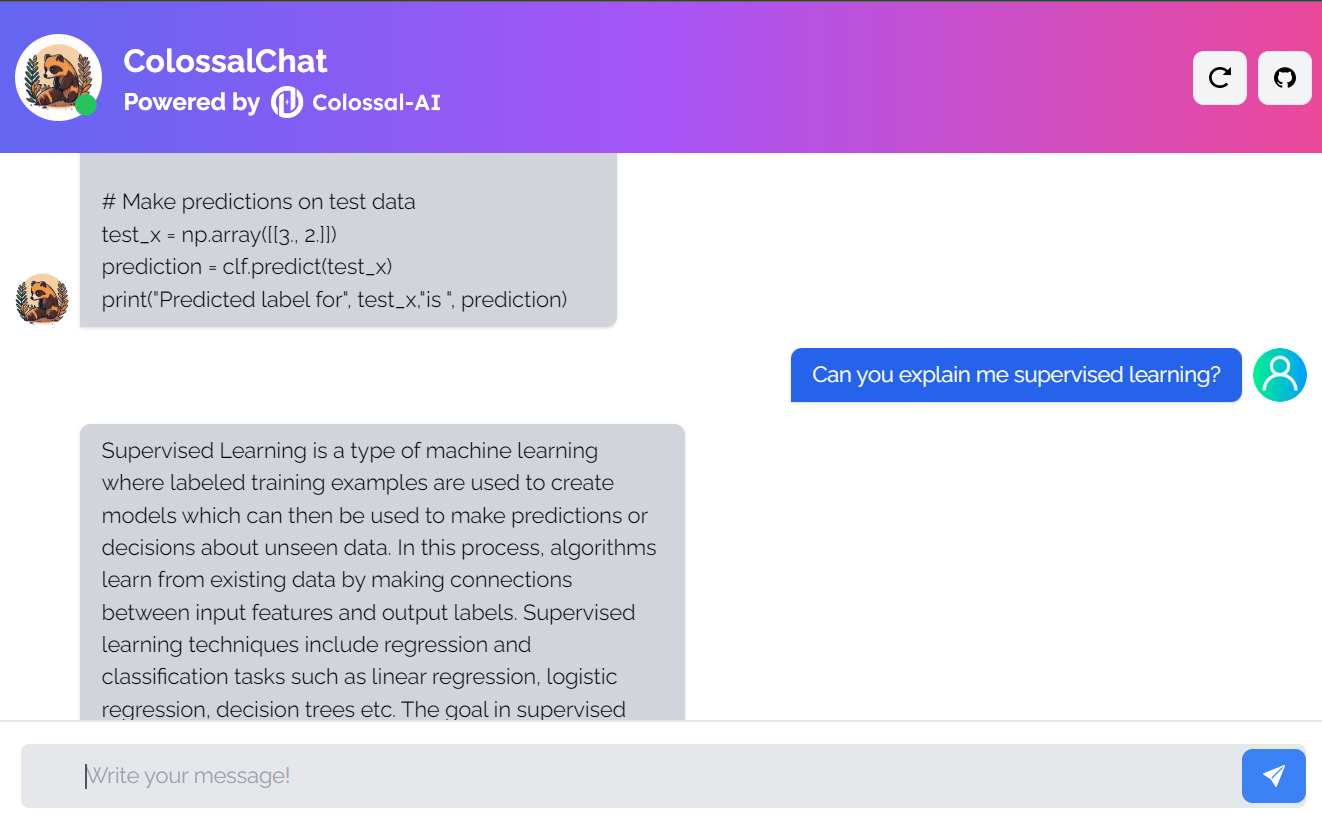
图片来自ColossalChat
- 研究论文:Colossal-AI:用于大规模并行训练的统一深度学习系统
- 博客文章:ColossalChat:用于克隆具有完整RLHF管道的ChatGPT的开源解决方案
- GitHub: hpcaitech/ColossalAI
- 演示:巨人聊天 (colossalai.org)
2. 羊驼-洛拉
Alpaca-LoRA是使用斯坦福羊驼和低秩适应(LoRA)创建的模型。低秩采用允许我们在 3.5GB RAM Raspberry Pi 4 上运行质量与 GPT-4 相似的 Instruct 模型。
该项目提供源代码、微调示例、推理代码、模型权重、数据集和演示。最好的部分是,我们可以在几个小时内在单个RTX 4090上训练我们的模型。
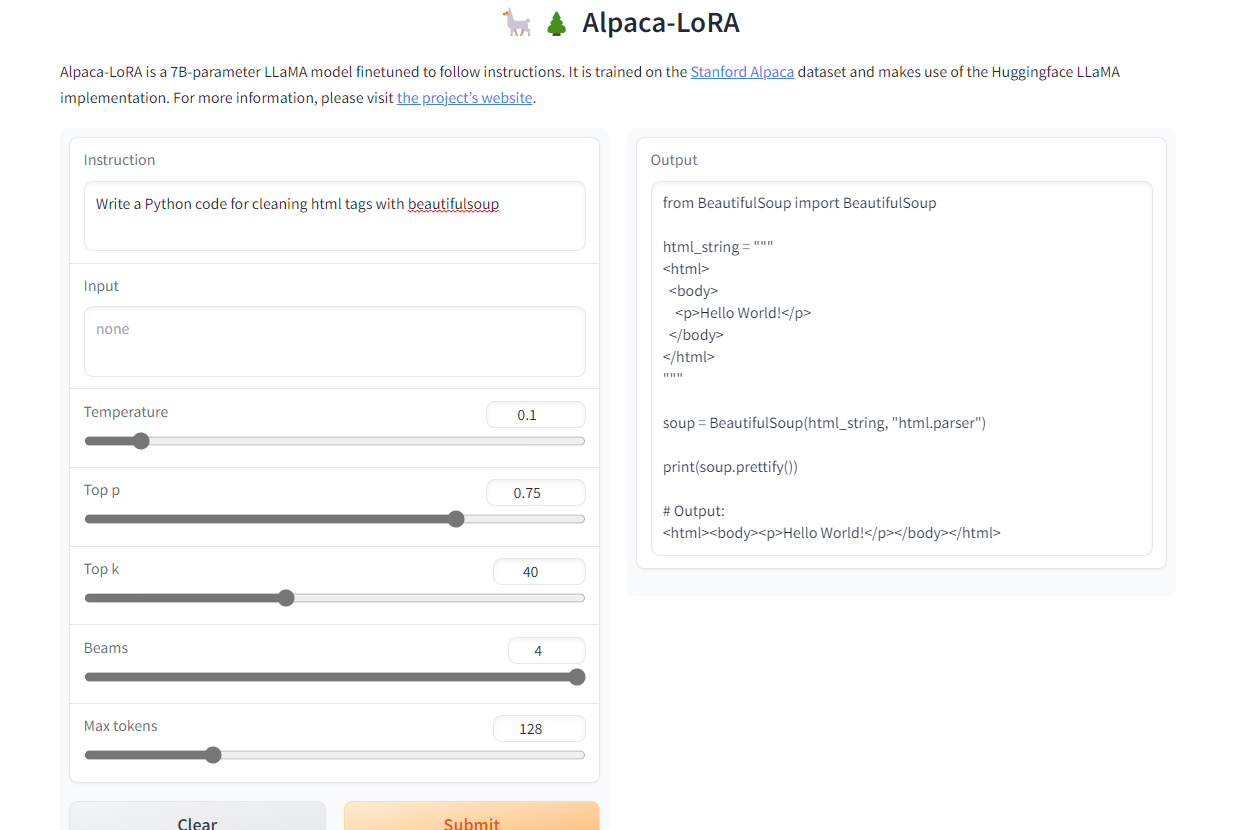
图片来自Alpaca-LoRA
- GitHub: tloen/alpaca-lora
- 模型卡:特洛恩/羊驼-洛拉-7b
- 演示:羊驼-洛拉
3. 骆马
骆马可以为聊天机器人生成连贯和创造性的文本。它是一种基于转换器的架构,在从 ShareGPT.com 收集的对话数据集上进行了微调。
骆马提供了近90%的ChatGPT性能。它是FastChat的一部分,FastChat是一个开放平台,允许用户培训,服务和评估他们的聊天机器人。FastChat 提供了构建自定义聊天机器人模型所需的所有组件和工具。
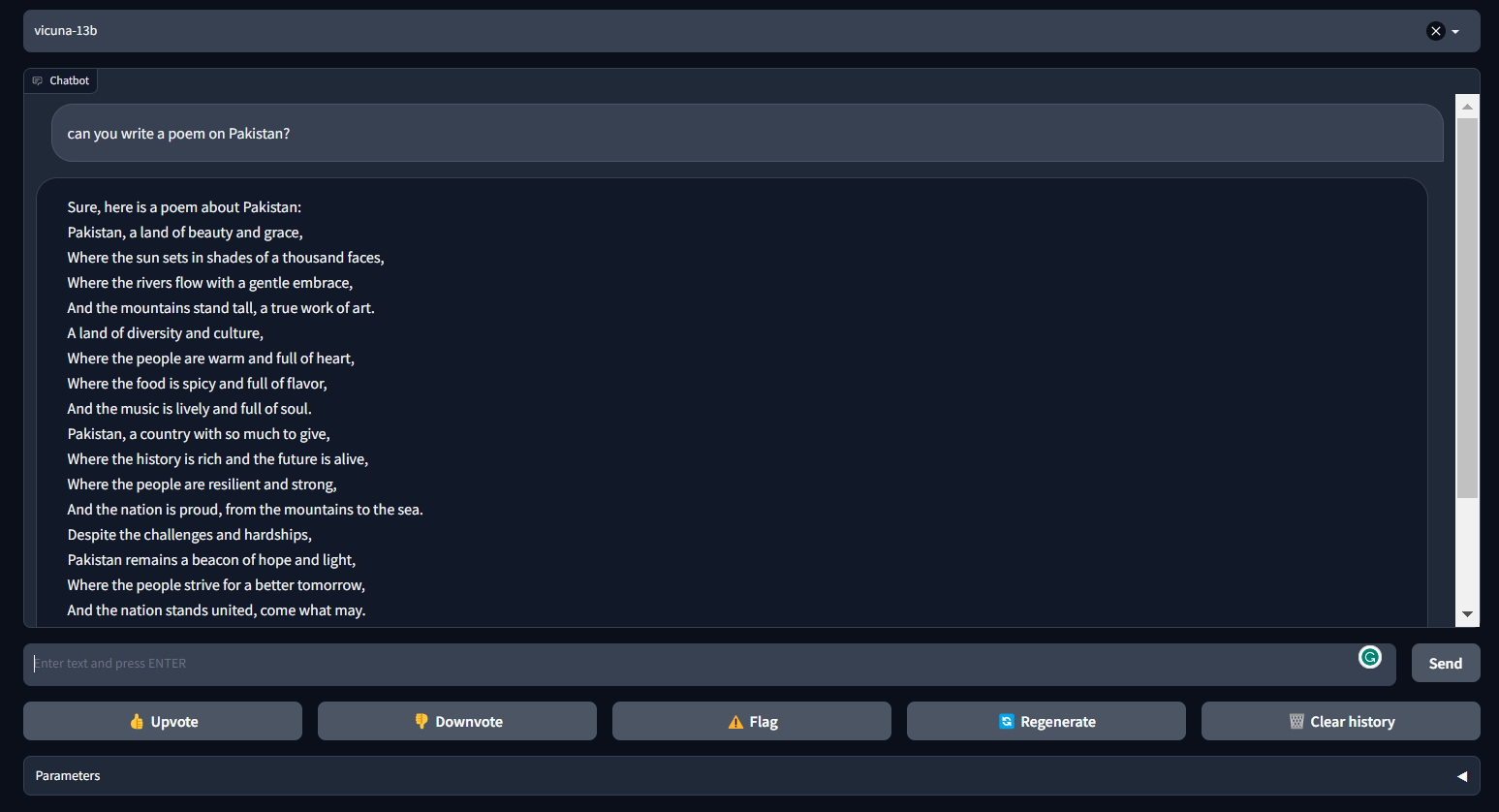
图片来自 FastChat (lmsys.org)
- 博客文章:Vicuna:一个开源聊天机器人,以 4%* 的 ChatGPT 质量给 GPT-90 留下深刻印象 | 由来自加州大学伯克利分校、CMU、斯坦福大学和加州大学圣地亚哥分校的成员组成
- GitHub: lm-sys/FastChat
- 演示:快速聊天 (lmsys.org)
4. GPT4ALL
GPT4ALL 是由 Nomic AI 团队开发的聊天机器人,用于处理大量辅助交互的精选数据,如单词问题、代码、故事、描述和多回合对话。该模型架构基于 LLaMa,它使用低延迟机器学习加速器在 CPU 上更快地进行推理。
使用 GPT4ALL,您可以获得 Python 客户端、GPU 和 CPU 干扰、Typescript 绑定、聊天界面和 Langchain 后端。
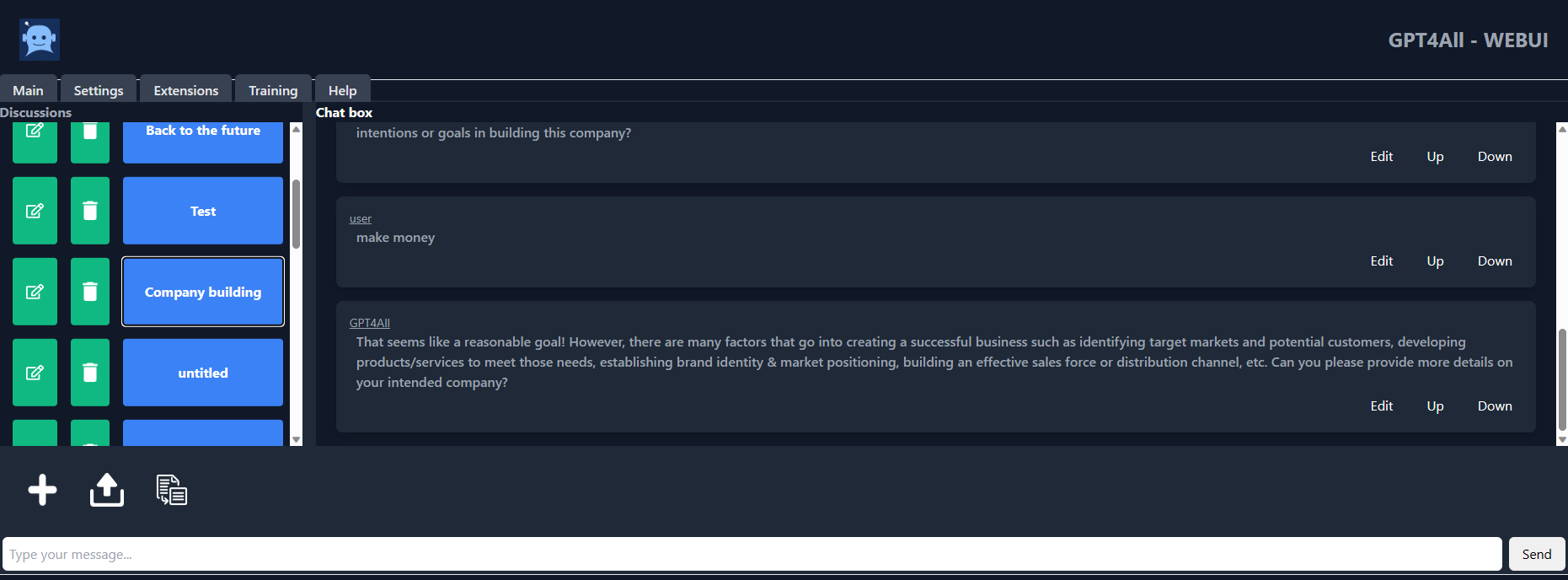
图片来自 gpt4all-ui
- 技术报告:GPT4全部
- GitHub: nomic-ai/gpt4al
- 聊天机器人UI:nomic-ai/gpt4all-ui
- 模型卡:nomic-ai/gpt4all-lora
5. 乌鸦 RWKV
Raven RWKV是ChatRWKV的一部分,ChatRWKV是一个类似于ChatGPT的开源模型,但由RWKV(100%RNN)语言模型提供支持,而不是基于变压器。
通过利用RNN,该模型实现了与变压器相当的质量和可扩展性水平,并具有更快的处理速度和VRAM节省的额外好处。Raven 被微调以遵循说明,并在斯坦福羊驼、code-alpaca 和更多数据集上进行了微调。
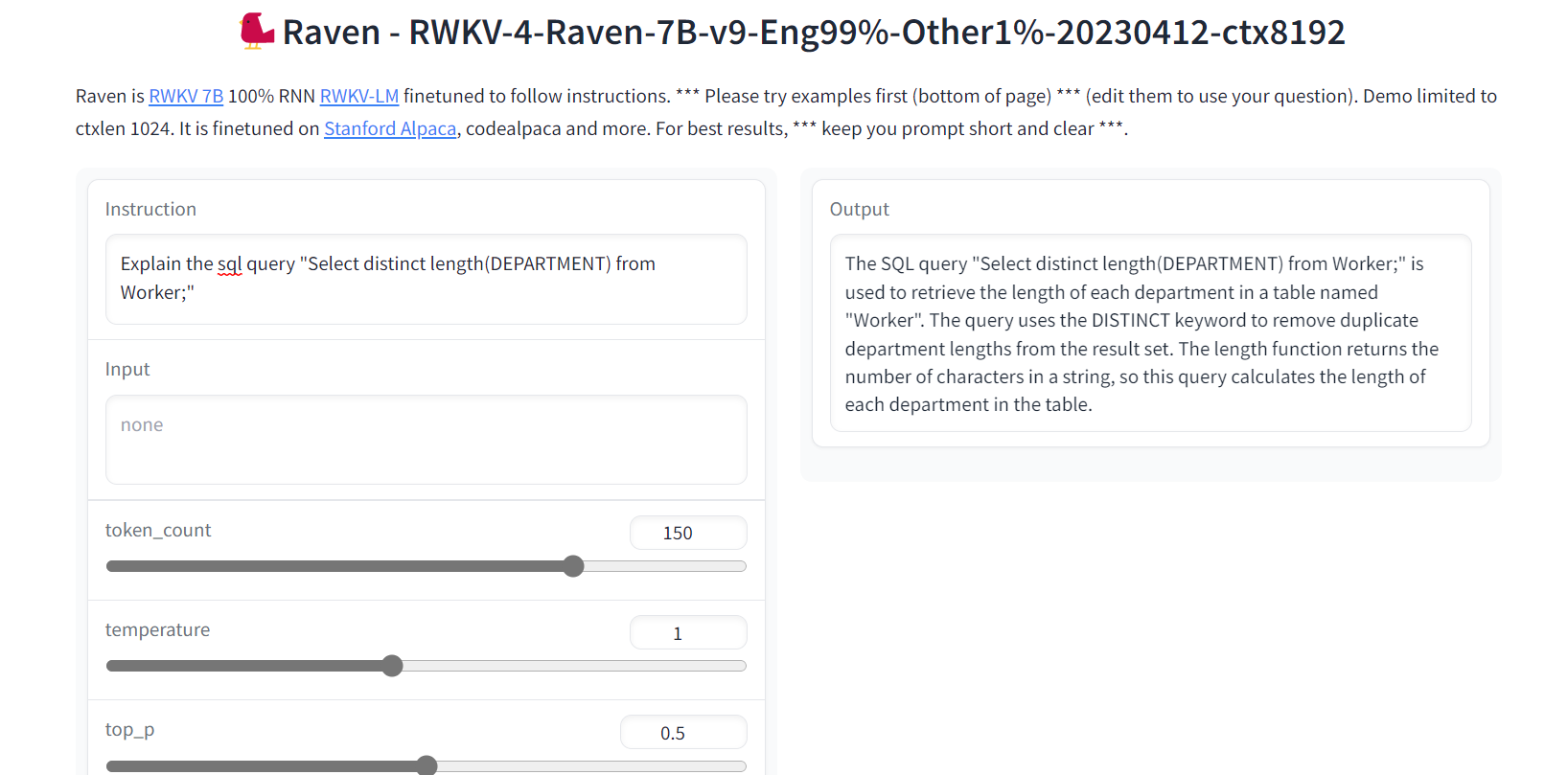
图片来自Raven RWKV 7B
- GitHub: BlinkDL/ChatRWKV
- 演示:乌鸦 RWKV 7B
- 型号卡:BlinkDL/rwkv-4-乌鸦
6. 打开聊天套件
OpenChatKit是一个全面的工具包,它为开发聊天机器人应用程序提供了ChatGPT的开源替代方案。
该工具包包括用于训练自己的指令优化大型语言模型、微调模型的分步说明,以及用于更新机器人响应的可扩展检索系统。此外,它还包括两种审核功能,可以帮助过滤掉不适当的问题。
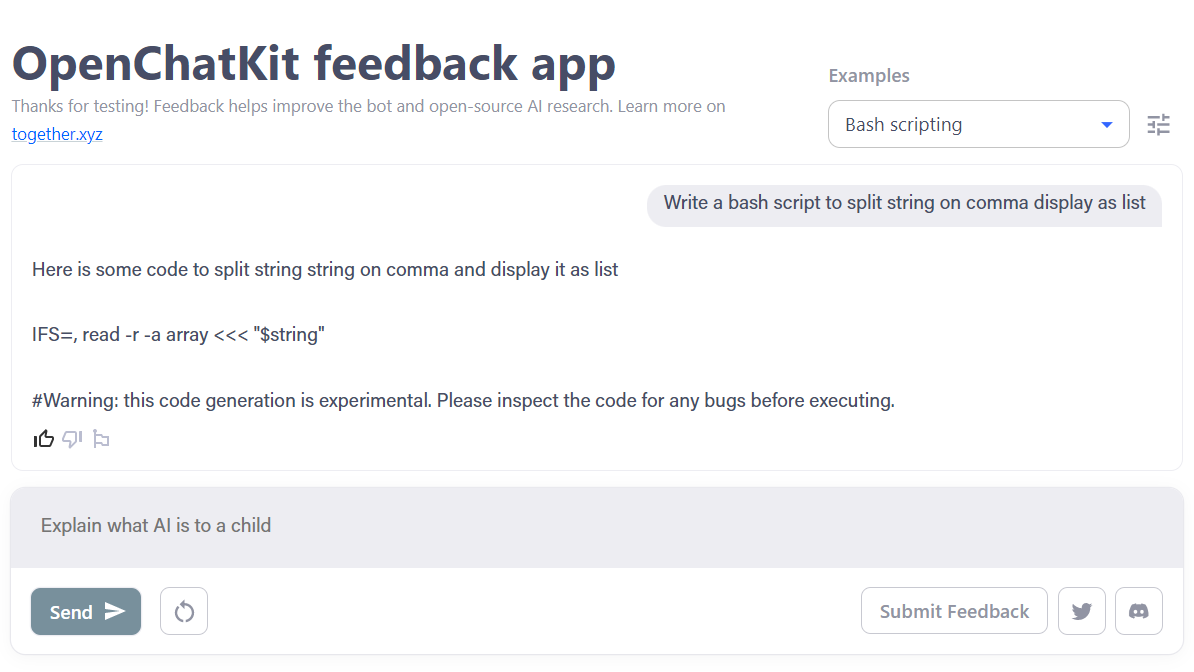
图片来自OpenChatKit
- 博客文章:宣布OpenChatKit — TOGETHER发布
- GitHub: togethercomputer/OpenChatKit
- 演示:开放聊天套件
- 模型卡:一起计算机/GPT-NeoXT-聊天基地-20B
7. 选择权
OPT(开放预训练变压器)语言模型在零镜头和少镜头学习以及刻板偏见分析方面表现出非凡的能力,尽管质量与 ChatGPT 不匹配。
OPT是一系列大型语言模型,参数范围从125M到175B。这些模型是仅解码器的转换器,这意味着它们从左到右生成文本自回归。
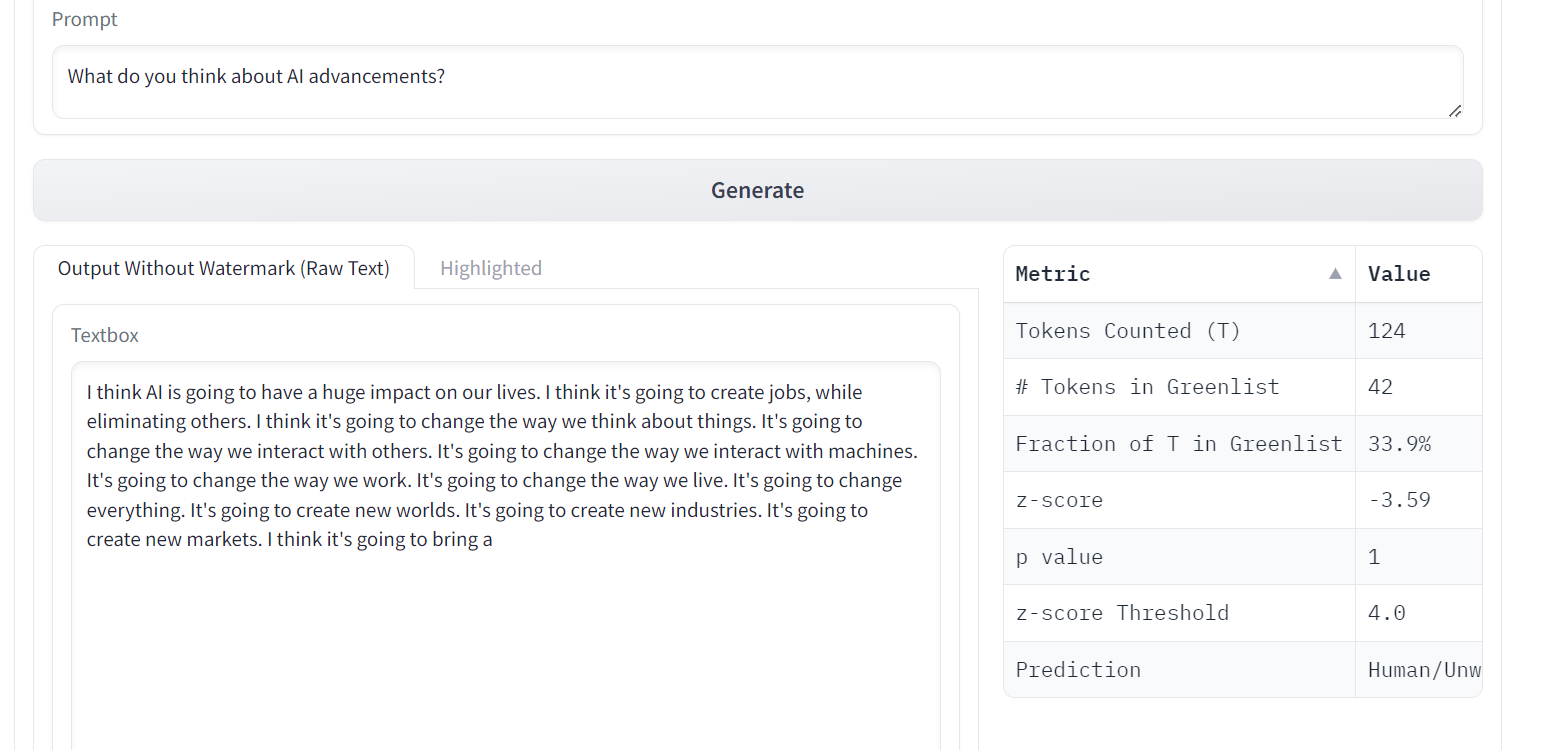
图片来自法学硕士水印
- 研究论文:OPT:开放预训练的转换器语言模型
- GitHub: facebookresearch/metaseq
- 演示:法学硕士的水印
- 模型卡:脸书/选择-1.3b
8. 弗兰-T5-XXL
Flan-T5-XXL是经过微调的T5模型,这些模型已经在以指令形式呈现的大量数据集上进行了训练。这种类型的微调显著提高了各种模型类(如 PaLM、T5 和 U-PaLM)的性能。此外,Flan-T5-XXL 模型针对涵盖多种语言的 1000 多个附加任务进行了微调。
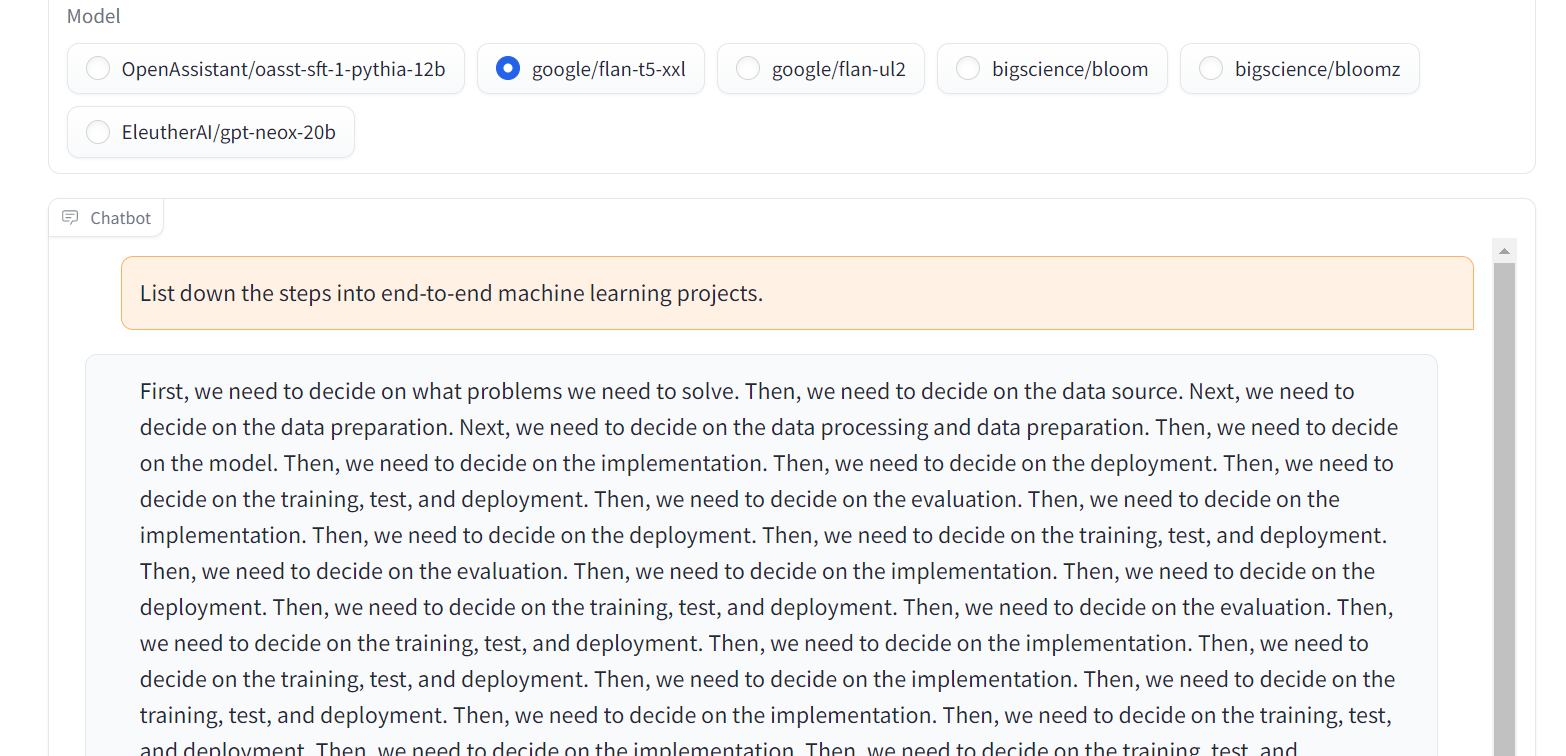
图片来自聊天LLM流
- 研究论文:扩展指令微调语言模型
- GitHub: google-research/t5x
- 演示:聊天LLM流
- 型号卡:谷歌/弗兰-T5-xxl
9.百泽
百泽在多回合对话中表现出令人印象深刻的表现,这要归功于其有助于降低潜在风险的护栏。它通过高质量的多轮聊天语料库实现了这一目标,该语料库是通过利用 ChatGPT 促进与自己的对话而开发的。
Baize 代码源、模型和数据集在非商业(研究目的)许可下发布。
 图片来自百泽7B
图片来自百泽7B
- 研究论文:百泽:对自聊数据进行参数高效调优的开源聊天模型
- GitHub:project-baize/baize-chatbot
- 演示:百泽7B
- 模型卡:项目-白泽/白泽-劳拉-7B
10. 考拉
考拉是一个聊天机器人,通过在从网络上抓取的对话数据集上微调LLaMa来训练。考拉的表现比羊驼更好,在许多情况下与ChatGPT相似。
考拉提供训练代码、公共权重和对话微调器,并经过 100 人的评估。
图片来自FastChat/Koala。
- 博客文章:考拉:学术研究的对话模式
- GitHub: young-geng/EasyLM
- 演示:快速聊天/考拉
11.多莉
Dolly是一个大型语言模型,由Databricks机器训练,以证明我们可以使用旧的开源语言模式,并赋予他们ChatGPT魔术指令跟随能力。模型训练需要在一台机器上使用高质量的训练数据进行 30 分钟。您甚至不需要大型模型即可实现高质量。该团队使用了 6 亿个参数模型,而 GPT-175 则为 3 亿个。
查看Dolly 2.0,这是一种可以商业使用的指令遵循语言模型。

图片来自 Hello Dolly
- 博客帖子:Hello Dolly:使用开放模型使 ChatGPT 的魔力民主化
- GitHub: databrickslabs/dolly
- 模型卡:数据砖/推车-v1-6b
12. 打开助手
Open Assistant 是一个真正的开源项目,这意味着每个人都可以访问基于聊天的大型语言模型。它旨在通过使人们能够与第三方系统交互、动态检索信息以及使用语言创建新应用程序来创造语言创新的革命。
您可以在单个高端消费者 GPU 上运行大语言聊天机器人,其代码、模型和数据根据开源许可证获得许可。
图片来自 open-assistant.io
- 博客帖子:开放助手第一模型来了!
- GitHub: LAION-AI/Open-Assistant
- 演示:open-assistant.io
- 模型卡:开放助手/绿洲-sft-1-皮西亚-12b
结论
这些 GPT-4 替代品可以帮助研究人员、开发人员和小公司创建基于语言的技术并与业内巨头竞争。这些模型的性能不高于 GPT-4,但随着时间的推移和社区的贡献,有些模型有可能超过 GPT-4。
如果您是 ChatGPT 的新手,请尝试参加我们的 ChatGPT 简介课程,如果您了解生成式 AI,您可以通过查看全面的 ChatGPT 数据科学备忘单或查看以下资源来更好地提示。